Tokenization for language modeling: BPE vs. Unigram Language Modeling (2020)
created: May 30, 2025, 8:59 a.m. | updated: May 30, 2025, 8:54 p.m.
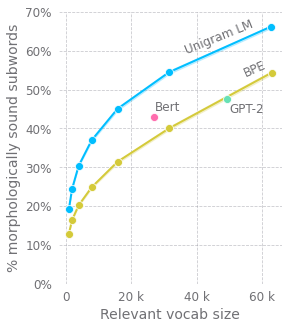
Byte pair encoding (BPE)The tokenizer used by GPT-2 (and most variants of Bert) is built using byte pair encoding (BPE).
Bert itself uses some proprietary heuristics to learn its vocabulary but uses the same greedy algorithm as BPE to tokenize.
Are we disadvantaging language models by partitioning words in ways that obscure the relationships between them?
Traditional NLP models used whole words as tokens which by definition have to be learned independently, so we're better off than we used to be!
The RoBERTa paper does consider tokenization in the Text Encoding section, but only compares variants of BPE (Bert's tokenizer and vanilla BPE).
1 week, 2 days ago: Hacker News