FastVLM: Efficient Vision Encoding for Vision Language Models
2bit
created: July 23, 2025, 5:09 p.m. | updated: July 24, 2025, 9:59 a.m.
Image Resolution and the Accuracy-Latency TradeoffGenerally, VLM accuracy improves with higher image resolution, especially for tasks needing detailed understanding, such as document analysis, UI recognition, or answering natural language queries about images.
As shown in Figure 2 below, both vision encoding and LLM pre-filling times grow as image resolution increases, and at high resolutions, vision encoder latency becomes the dominant bottleneck.
To address this, our research introduces FastVLM, a new vision language model that significantly improves efficiency without sacrificing accuracy.
was kept the same, and only the vision encoder was changed.
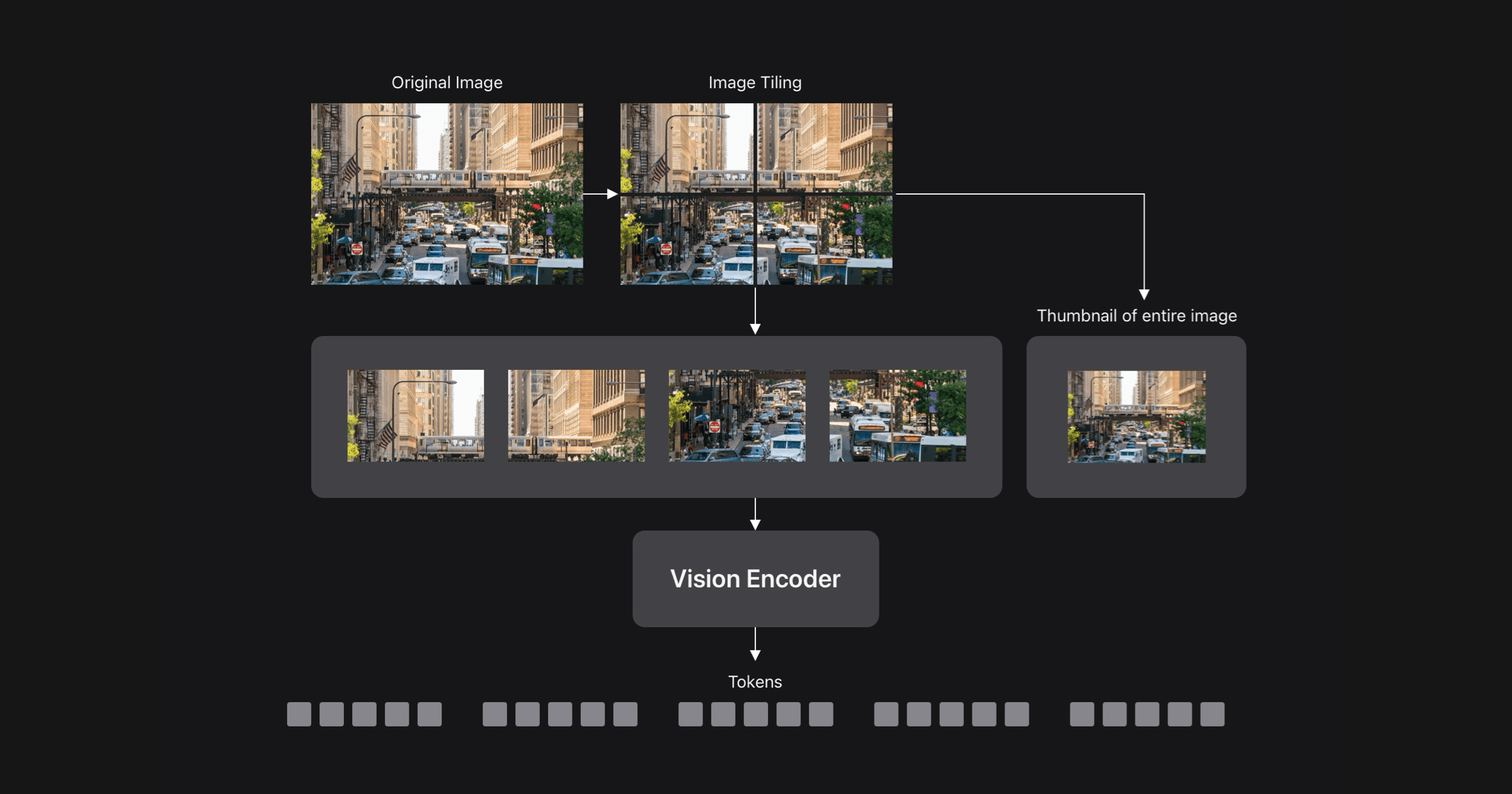
FastVLM addresses this tradeoff by leveraging a hybrid-architecture vision encoder built for high-resolution images, FastViTHD.
1 week, 4 days ago: Hacker News: Front Page